
1 引言
當前企業面對百花齊放的大模型生態,普遍缺乏科學的選型依據。特別是在DeepSeek等開源大模型掀起技術變革浪潮的背景下,如何科學評估不同模型的真實能力,并基于評測結果指導大模型后續開發優化,已成為AI落地的關鍵挑戰。正如孫子所言“知己知彼,百戰不殆”——只有深度了解現有模型的能力邊界,才能明確自身的技術需求與發展方向。基于這一理念,我司深耕AI核心技術開發,在深度學習理論與架構優化、分布式計算與訓練優化和大模型業務場景定制化優化等核心技術領域積累深厚底蘊,研發推出大模型評測系統:一款面向大語言模型全生命周期評估的智能化平臺。
模型評測系統采用主觀評測和客觀評測雙引擎評測架構,主觀評測通過"自提問模式"與"問卷模式"結合,基于真實用戶交互與標準化任務測試,精準評估大模型在對話生成、文本創作、代碼編寫等多種場景下的實際表現;客觀評測基于多個權威公開數據集,采用標準化指標進行量化分析。通過科學的評測方法論,為企業提供可靠的選型依據和開發指導,實現"融通致遠"的技術愿景。
模型評測系統構建了五大核心功能模塊,全面覆蓋模型評測需求。
1) 主觀 交互式評測功能通過“自提問模式”和“問卷模式”,允許用戶與模型進行實時互動,在對話、代碼生成等多種任務場景中進行自由測試,基于語言流暢性、邏輯推理能力、準確性等維度進行多輪動態評分,自提問模式和問卷模式分別為圖1、圖2所示。
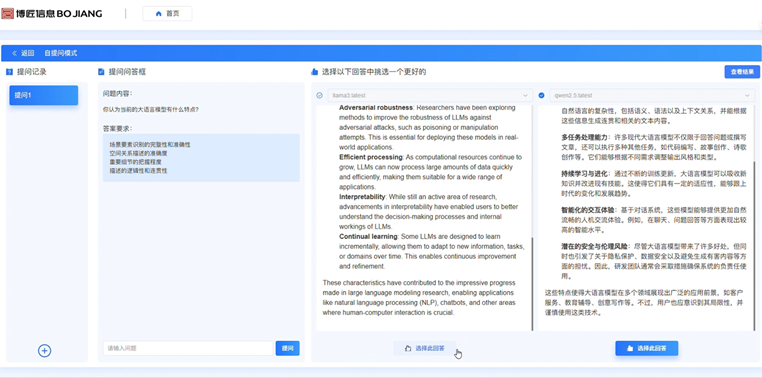
圖1 自提問模式
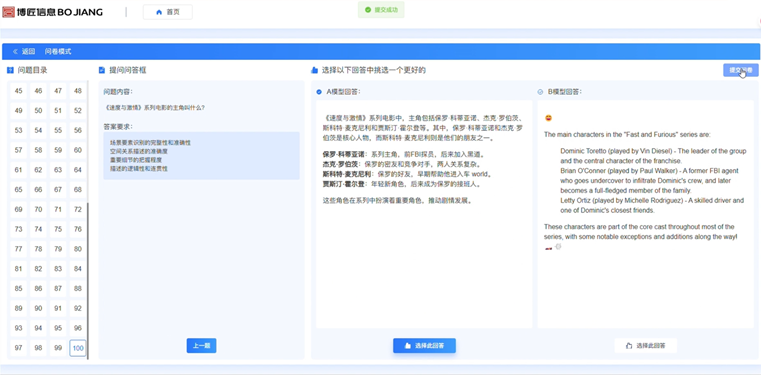
圖2問卷模式
2) 自動化客觀評測功能基于MMLU、Math和C-Eval等權威公開數據集,一鍵執行自動化評測,快速生成多維度、可量化的性能對比,部分評測結果如圖3示。
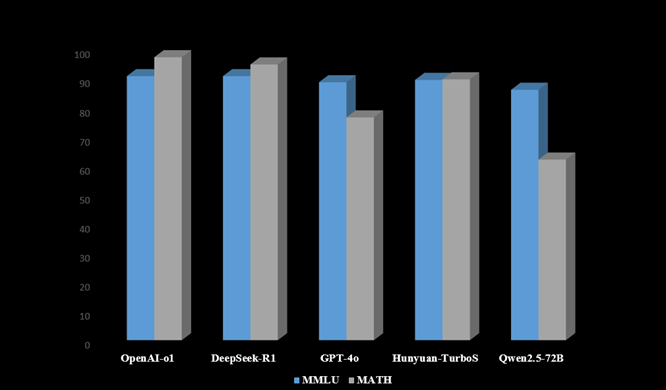
圖3不同模型在MMLU、MATH上的評測結果
3) 綜合指標分析功能內置10余項核心評測維度,包括用戶滿意度、指令遵循能力、安全性檢測等,結合ROUGE、BLEU等客觀指標與主觀評分,確保評估結果的全面性和準確性。
4) 多源數據管理功能不僅集成權威公開數據集,更支持企業私有數據的加密接入,滿足不同行業的定制化評測需求。
5) 可視化分析與報告功能通過雷達圖、熱力圖等圖形化方式直觀展示模型能力分布,支持多模型性能對比分析,并提供自動化報告生成功能,一鍵導出包含得分詳情、短板分析與改進建議的完整評測報告,如圖4示。
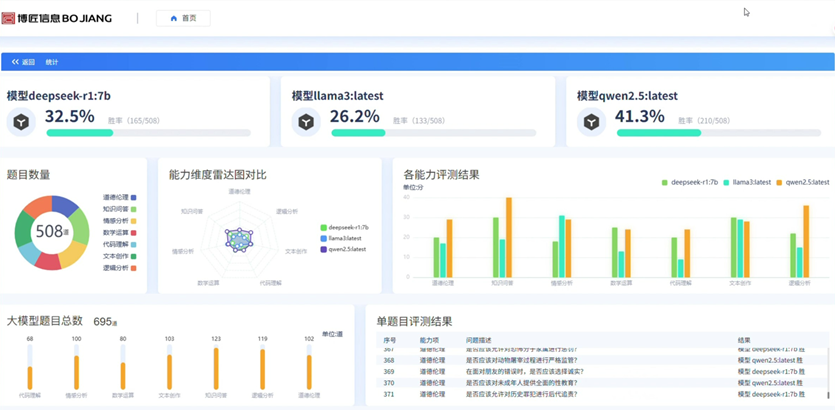
圖4模型評測結果可視化展示
模型評測系統的突出優勢體現在創新的評測方法論和全面的技術保障上。在評測方法方面,系統的雙引擎驅動模式將靜態數據集評測與動態用戶交互評測相結合,真實反映模型在實際應用中的表現。極致評測效率體現在平臺支持百萬級數據并行評測,通過分布式計算架構實現處理速度提升3倍以上。在技術架構方面,系統兼容HuggingFace全系列、GPT-4/3.5、文心一言、通義千問等50+ 主流開源/API模型,具備強大的模型適配能力。在安全保障方面,系統支持私有化部署,確保數據隔離與合規性要求,數據采用AES-256加密存儲,符合ISO 27001、等保三級等國際安全標準。同時,系統提供公有云SaaS服務和私有化部署兩種靈活的部署方式,無縫適應不同企業的安全和技術要求。
模型評測系統是模型研發、選型與優化的有效工具,可廣泛應用于大模型研發優化、企業模型選型決策場景、行業解決方案適配場景、學術研究與權威競賽等場景。
在AI技術加速演進的時代背景下,科學的模型評測已成為企業數字化轉型的核心驅動力。我司大模型評測系統以"知彼之能,明己之需"為設計理念,通過雙引擎評測架構與全方位技術保障,為企業構建從選型決策到優化部署的完整AI治理體系。面向未來,我們將持續深化評測技術創新,緊跟行業前沿趨勢,讓每一次模型選擇都有據可依,每一項AI投入都物有所值,助力企業真正實現"融通致遠"的智能化發展愿景。
